
Code inspection for zero width non-printable chars

Warning: This post covers scenarios when non-printable characters are entered by you during development process. Sanitization of user or 3rd party API input is a completely different topic.
Welcome to the world of non-printable UTF-8 characters. They are easy to miss in the editor and can cause various issues in the code. Especially when using the same text string in different languages which treat them in their own way.
Examples
Most common non-printable Unicode characters which you may encounter are:
- \u200b: zero width space
- \u200c: zero width non-joiner
- \u200d: zero width joiner
- \ufeff: zero width no-break space
- \u2028: line separator
- \u2029: paragraph separator
What are the dangers?
There are multiple issues which occur, their severity level depends on the context in which those characters exist in the code.
JavaScript
Due to some design inconsistencies line and paragraph separators are perfectly valid characters in JSON world but will cause a SyntaxError: Unexpected token ILLEGAL when used in JavaScript.
Modern browsers and JSON parsing libraries have methods to overcome that issue but you can still introduce it easily by passing variables from PHP (or other backend language) to JS by using common var x = '<?= $php_var;?>'; method.
If you are interested to read more please visit this great article about JavaScript and JSON
Example above is just a tip of an iceberg as errors may vary depending on the context in which those characters exist. Try to search for "non-printable characters" at StackOverflow and you can get more than 2,000 results.
HTML/CSS
Alternatively if those characters end up in template you may see various styling issues - those characters are most of the time properly rendered by browser so do not be surprised from having weird gaps when there is "nothing" in CSS and there is no visible markup. Simply browser can interpret your invisible \u2028\ character as regular line break and apply spacing in there.
How they landed in my code?
It is difficult to enter them on purpose but it is very easy to introduce those characters via simple copy-paste. Most of the common sources might be a PDF, MSWord document or simple output of Google Chrome Developer Tools edit HTML mode.
How to spot them outside editor?
If you are very lucky and the error exists only in HTML then you might spot red dots in Chrome Dev Tools (edit HTML mode) which are representing non-printable characters.
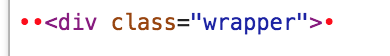
There is also chance that the browser will output some weird characters to the screen indicating that there is an issue. That may depend on browser encoding settings, used fonts or placement of such character.

If you are less lucky though then you may get weird, uncommon SyntaxError: Unexpected token ILLEGAL JavaScript errors. If there is no clear and visible syntax issue in the code then it may be caused by aforementioned non-printable characters.
How to solve it?
Some of the editors have possibility to highlight non-printable characters by adjusting its settings.
If you use the one and only PHPStorm (as me) then Victor Rosenberg wrote a plugin called Zero width character locator which scans your code in order to detect various "sneaky little bastards". The plugin can be downloaded from the link below or installed directly from PHPStorm settings.
http://plugins.jetbrains.com/plugin/7448
Activate it and voilà - you have the inspection results directly in your code editor window. If that is not enough then you have also a possibility to scan complete project directory and find all problematic occurrences.
After fixing the issue you may notice the difference in git diff output:

I hope that this helps someone. Let me know if you have any questions!